
🧬 Model Identity
This is not a pre-trained model with fine-tuning. It is a Hellenic AI with Custom Neural Network Architecture (based on the byT5 architecture developed by Google Research), where we redesigned the structure to achieve maximum optimization exclusively for the Greek internet language.
🧠 Custom Neural Architecture
The innovation lies in the "setup" of the neural network, stepping away from standard conventions.
1. Custom Layering: Definition of Encoder/Decoder Layers for maximum performance without unnecessary computational cost.
2. Attention Heads: Definition of Attention Heads for more accurate focusing on error patterns and phonetic peculiarities.
3. Neuron Density: Definition of neurons (Hidden Size / Feed Forward Layers) for a balance between speed and accuracy.
A fast model is a reliable model.
🚀 Model Capabilities
The model operates as a Deep Learning Corrector with capabilities that go beyond standard rules:
1. Greeklish & Phonetic Correction: Conversion of even the most unorthodox Greeklish into authentic Greek (e.g. "pragmatophhsooume" -> "πραγματοποιήσουμε").
2. Fat-Finger & Typo: Greek - English correction of adjacent key errors and accidental presses (e.g. "περνούσςν" -> "περνούσαν").
3. Layout Detection: English automatic detection and correction of wrong keyboard language (e.g. "μερψεδες" -> "mercedes").
4. Morphological Restoration: Greek - English reconstruction of word spelling based on morphology, regardless of syntax (e.g. "πολυάρηθμα" -> "πολυάριθμα").
🔮 Master Model Roadmap (Phase 2)
The model's evolution aims to create the most specialized tool for E-commerce Search Engines and Data Cleaning:
Ecosystem Strategy: Creation of an ecosystem of smaller, specialized models (Distilled Models) derived from the Master Model, so that each specialty always has maximum speed.
1. Massive Scale: Vocabulary expansion to 1,500,000 unique words (Greek - English).
2. Hyper-Training: Training on 100,000,000+ data variations.
Entity Recognition Capabilities:
📧 Emails: Correction of typos in addresses (e.g. @gmil.com -> @gmail.com).
📦 SKUs: Recognition of product codes.
🗣️ Slang & Argo: Understanding of daily language and idioms.
🔢 Alphanumerics: Management of numbers, dates, and codes.
📊 Training Metrics & Performance | Project Manaraki (V3)
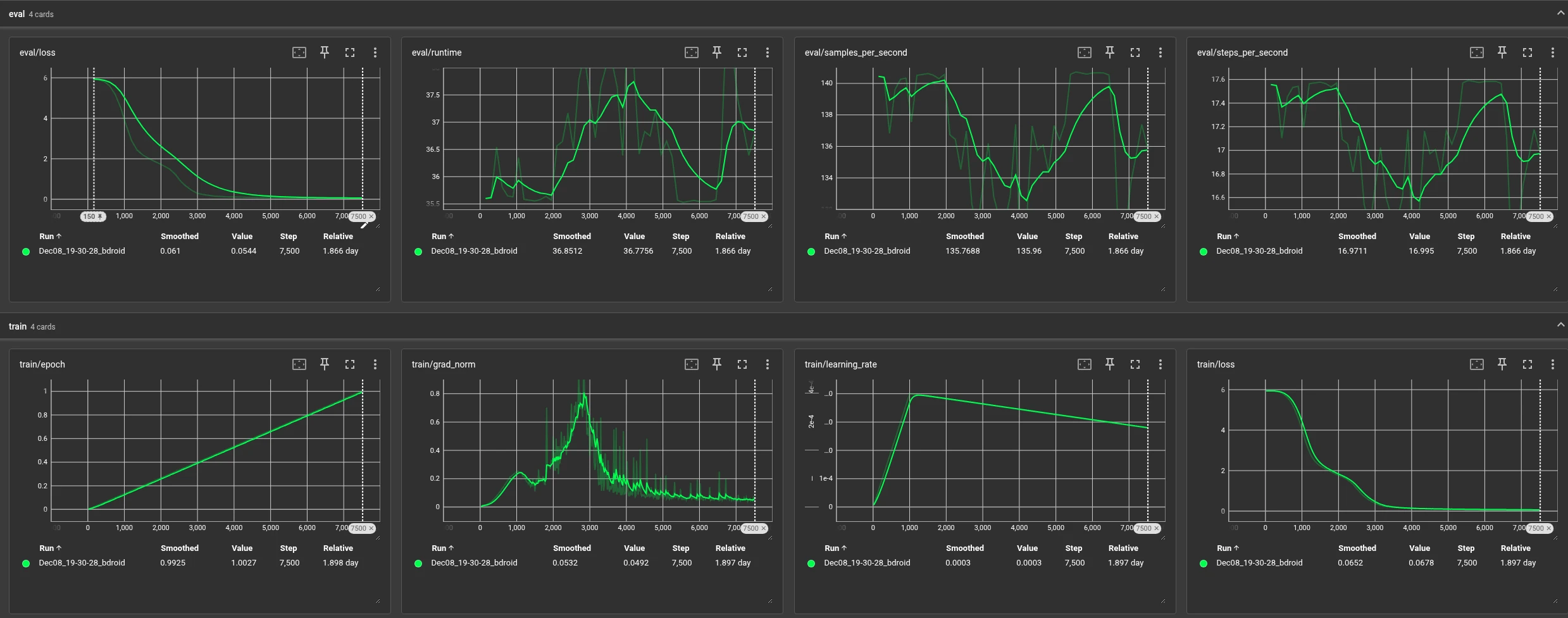
The model training was completed in 7,500 steps (1 Epoch). As shown in the logs, the model achieved Validation Loss < 0.06, proving its ability to perceive and correct complex Noise Patterns, while avoiding the phenomenon of Overfitting.
Transparency: Download the full log file with 2,000+ real test examples.
📄 Download Results (TXT)