
🧬 Η Ταυτότητα του Μοντέλου
Αυτό δεν είναι ένα προ-εκπαιδευμένο μοντέλο με fine-tuning. Πρόκειται για ένα Ελληνικό AI με Custom Αρχιτεκτονική Νευρωνικών Δικτύων (τύπου byT5 που ανέπτυξε η Google Research), όπου επανασχεδιάσαμε τη δομή για να επιτύχουμε τη μέγιστη βελτιστοποίηση αποκλειστικά για την Ελληνική γλώσσα του διαδικτύου.
🧠 Custom Neural Architecture
Η καινοτομία είναι στο "στήσιμο" του νευρωνικού δικτύου, χωρίς να ακολουθούμε την πεπατημένη.
1. Custom Layering: Ορισμός των Encoder/Decoder Layers για μέγιστη απόδοση χωρίς περιττό υπολογιστικό κόστος.
2. Attention Heads: Ορισμός κεφαλών προσοχής (Attention Heads) για ακριβέστερη εστίαση σε μοτίβα λαθών και φωνητικές ιδιαιτερότητες.
3. Neuron Density: Ορισμός νευρώνων (Hidden Size / Feed Forward Layers) για ισορροπία μεταξύ ταχύτητας και ακρίβειας.
Γρήγορο μοντέλο είναι το σίγουρο μοντέλο.
🚀 Δυνατότητες Μοντέλου
Το μοντέλο λειτουργεί ως ένας Διορθωτής Deep Learning με δυνατότητες που ξεπερνούν τους κανόνες:
1. Greeklish & Phonetic Correction: Μετατροπή ακόμη και των πιο ανορθόδοξων Greeklish σε αυθεντικά Ελληνικά (π.χ. "pragmatophhsooume" -> "πραγματοποιήσουμε").
2. Fat-Finger & Typo: Ελληνικά - Αγγλικά διόρθωση λαθών γειτονικών πλήκτρων και τυχαίων πατημάτων (π.χ. "περνούσςν" -> "περνούσαν").
3. Layout Detection: Αγγλικά αυτόματη ανίχνευση και διόρθωση λανθασμένης γλώσσας πληκτρολογίου (π.χ. "μερψεδες" -> "mercedes").
4. Morphological Restoration: Ελληνικά - Αγγλικά αναδόμηση της ορθογραφίας της λέξης βάσει μορφολογίας, ανεξάρτητα από το συντακτικό (π.χ. "πολυάρηθμα" -> "πολυάριθμα").
🔮 Master Model Roadmap (Phase 2)
Η εξέλιξη του μοντέλου στοχεύει στη δημιουργία του πλέον εξειδικευμένου εργαλείου για E-commerce Search Engines και Data Cleaning:
Ecosystem Strategy: Δημιουργία οικοσυστήματος μικρότερων, εξειδικευμένων μοντέλων (Distilled Models) που προκύπτουν από το Master Model, ώστε κάθε ειδικότητα να έχει πάντα τη μέγιστη ταχύτητα.
1. Massive Scale: Επέκταση του λεξιλογίου σε 1.500.000 μοναδικές λέξεις (Ελληνικά - Αγγλικά).
2. Hyper-Training: Εκπαίδευση σε 100.000.000+ παραλλαγές δεδομένων.
Entity Recognition Capabilities:
📧 Emails: Διόρθωση typos σε διευθύνσεις (π.χ. @gmil.com -> @gmail.com).
📦 SKUs: Αναγνώριση κωδικών προϊόντων.
🗣️ Slang & Argo: Κατανόηση καθημερινής γλώσσας και ιδιωματισμών.
🔢 Alphanumerics: Διαχείριση αριθμών, ημερομηνιών και κωδικών.
📊 Training Metrics & Performance | Project Μαναράκι (V3)
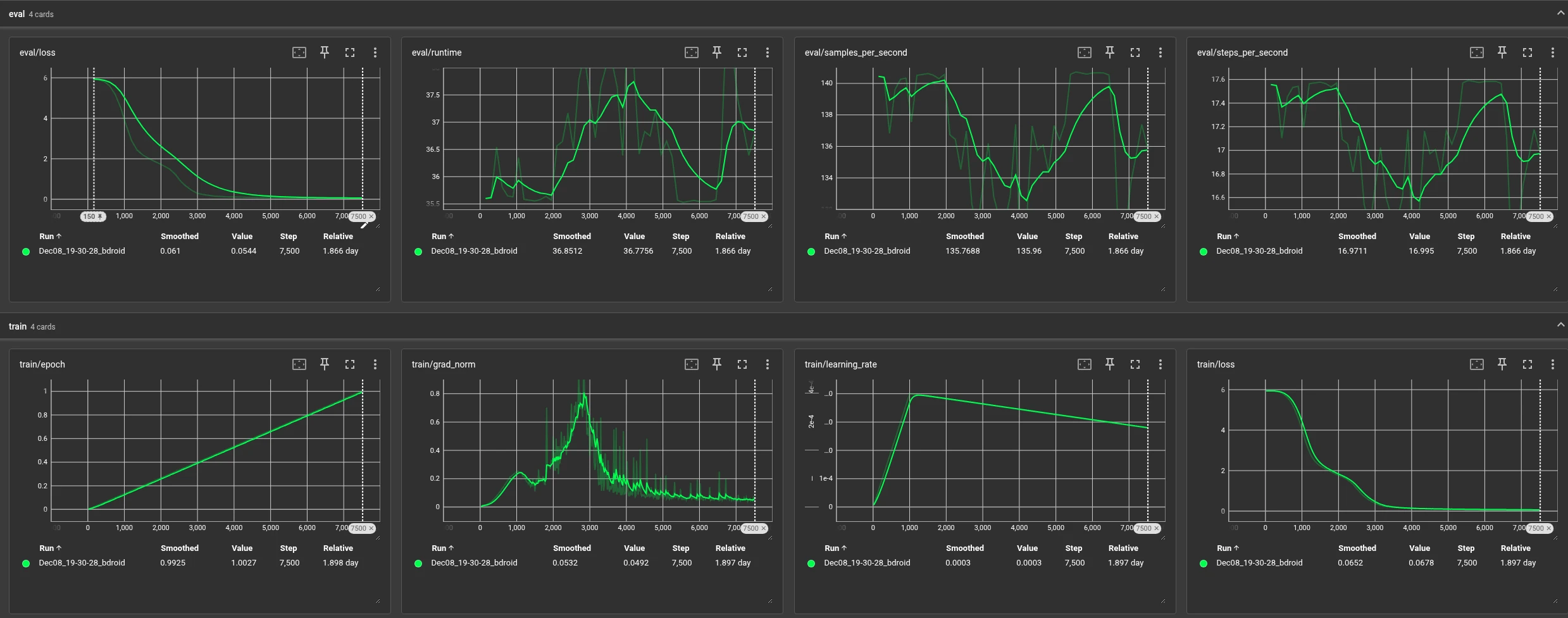
Η εκπαίδευση του μοντέλου ολοκληρώθηκε σε 7.500 βήματα (1 Epoch). Όπως φαίνεται από τα logs, το μοντέλο πέτυχε Validation Loss < 0.06, αποδεικνύοντας την ικανότητά του να αντιλαμβάνεται και να διορθώνει σύνθετα μοτίβα θορύβου (Noise Patterns), αποφεύγοντας το φαινόμενο του Overfitting.
Διαφάνεια: Κατεβάστε το πλήρες αρχείο logs με 2.000+ πραγματικά παραδείγματα δοκιμών.
📄 Κατέβασε τα αποτελέσματα (TXT)